 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Workbench for Acquisition of Domain Knowledge from Natural Language
Apr 30, 1996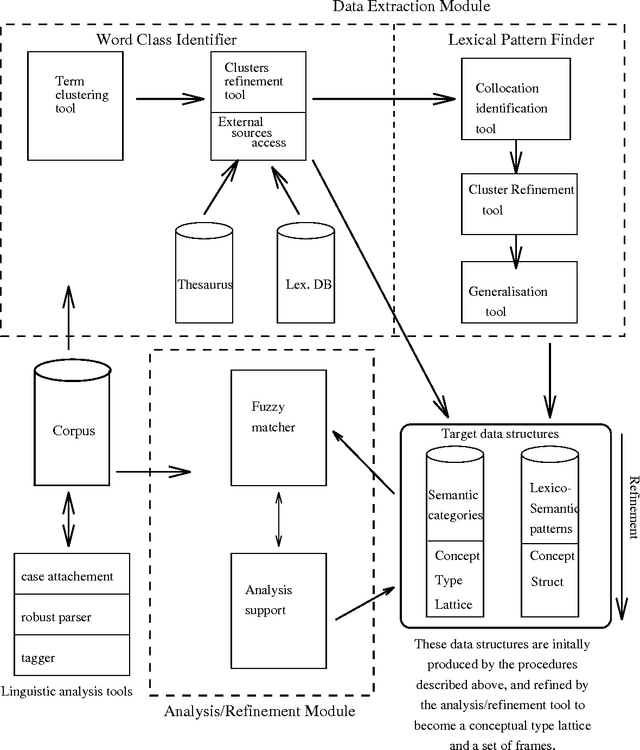
In this paper we describe an architecture and functionality of main components of a workbench for an acquisition of domain knowledge from large text corpora. The workbench supports an incremental process of corpus analysis starting from a rough automatic extraction and organization of lexico-semantic regularities and ending with a computer supported analysis of extracted data and a semi-automatic refinement of obtained hypotheses. For doing this the workbench employs methods from computational linguistics, information retrieval and knowledge engineering. Although the workbench is currently under implementation some of its components are already implemented and their performance is illustrated with samples from engineering for a medical domain.
Unsupervised Learning of Word-Category Guessing Rules
Apr 30, 1996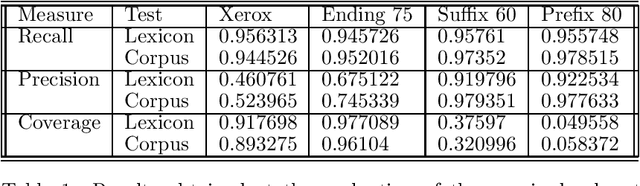
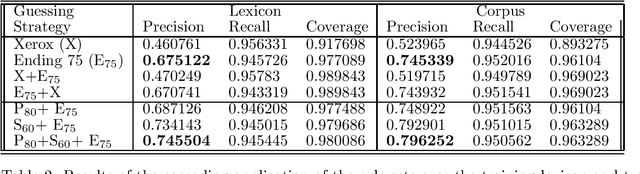
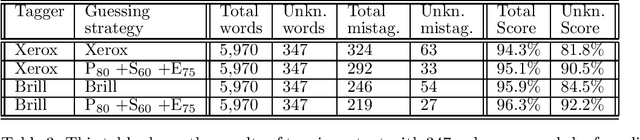
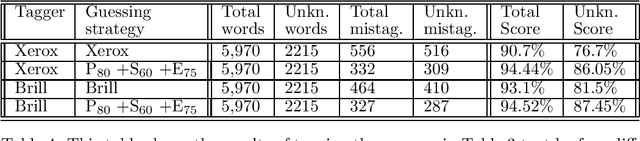
Words unknown to the lexicon present a substantial problem to part-of-speech tagging. In this paper we present a technique for fully unsupervised statistical acquisition of rules which guess possible parts-of-speech for unknown words. Three complementary sets of word-guessing rules are induced from the lexicon and a raw corpus: prefix morphological rules, suffix morphological rules and ending-guessing rules. The learning was performed on the Brown Corpus data and rule-sets, with a highly competitive performance, were produced and compared with the state-of-the-art.
Learning Part-of-Speech Guessing Rules from Lexicon: Extension to Non-Concatenative Operations
Apr 30, 1996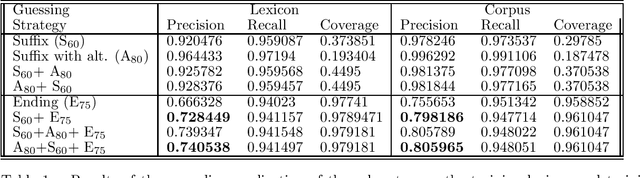
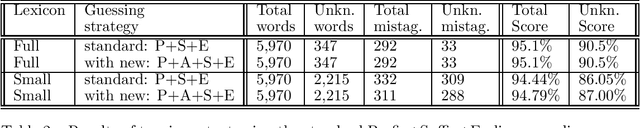
One of the problems in part-of-speech tagging of real-word texts is that of unknown to the lexicon words. In Mikheev (ACL-96 cmp-lg/9604022), a technique for fully unsupervised statistical acquisition of rules which guess possible parts-of-speech for unknown words was proposed. One of the over-simplification assumed by this learning technique was the acquisition of morphological rules which obey only simple concatenative regularities of the main word with an affix. In this paper we extend this technique to the non-concatenative cases of suffixation and assess the gain in the performance.